P53 · 评测理念
理念转变:LLM as Judge → Agent as Judge
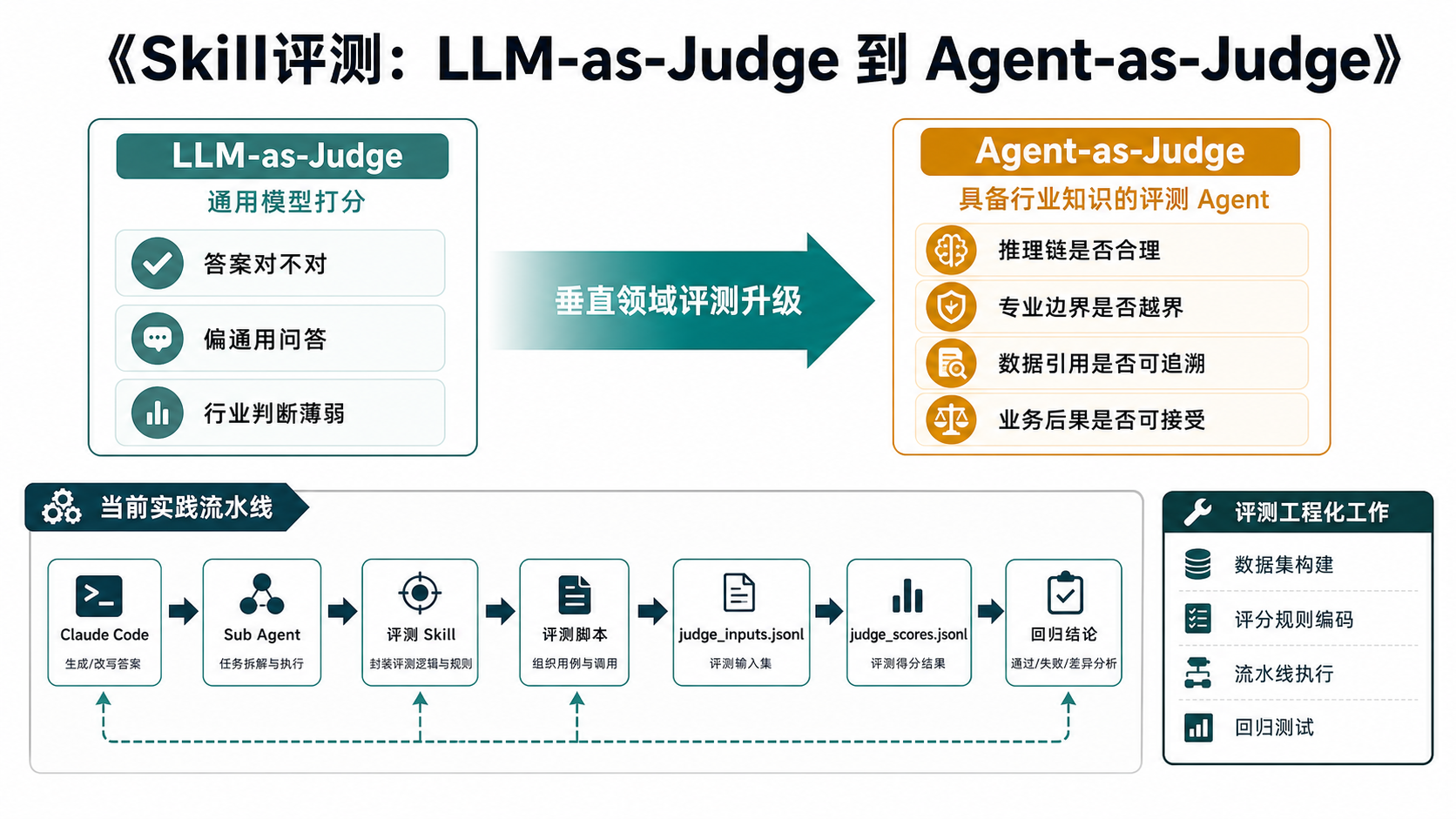
《Skill 评测:LLM-as-Judge 到 Agent-as-Judge》
LLM-as-Judge 只看"这一句答得对不对";Agent-as-Judge 看"整个任务做得好不好" —— 评测主体也要会干活。
P54 · 指标设计
评测指标设计:红线 + 质量层
红线层 · 一票否决
不过线,质量层再高都没有意义。
数据准确率 100%
不造数据
不靠检索 / 记忆作答
质量层 · 综合回答质量
任务完成度业务
事实准确性业务
业务诉求覆盖业务
证据可追溯技术
边界与风险技术
业务表达表达
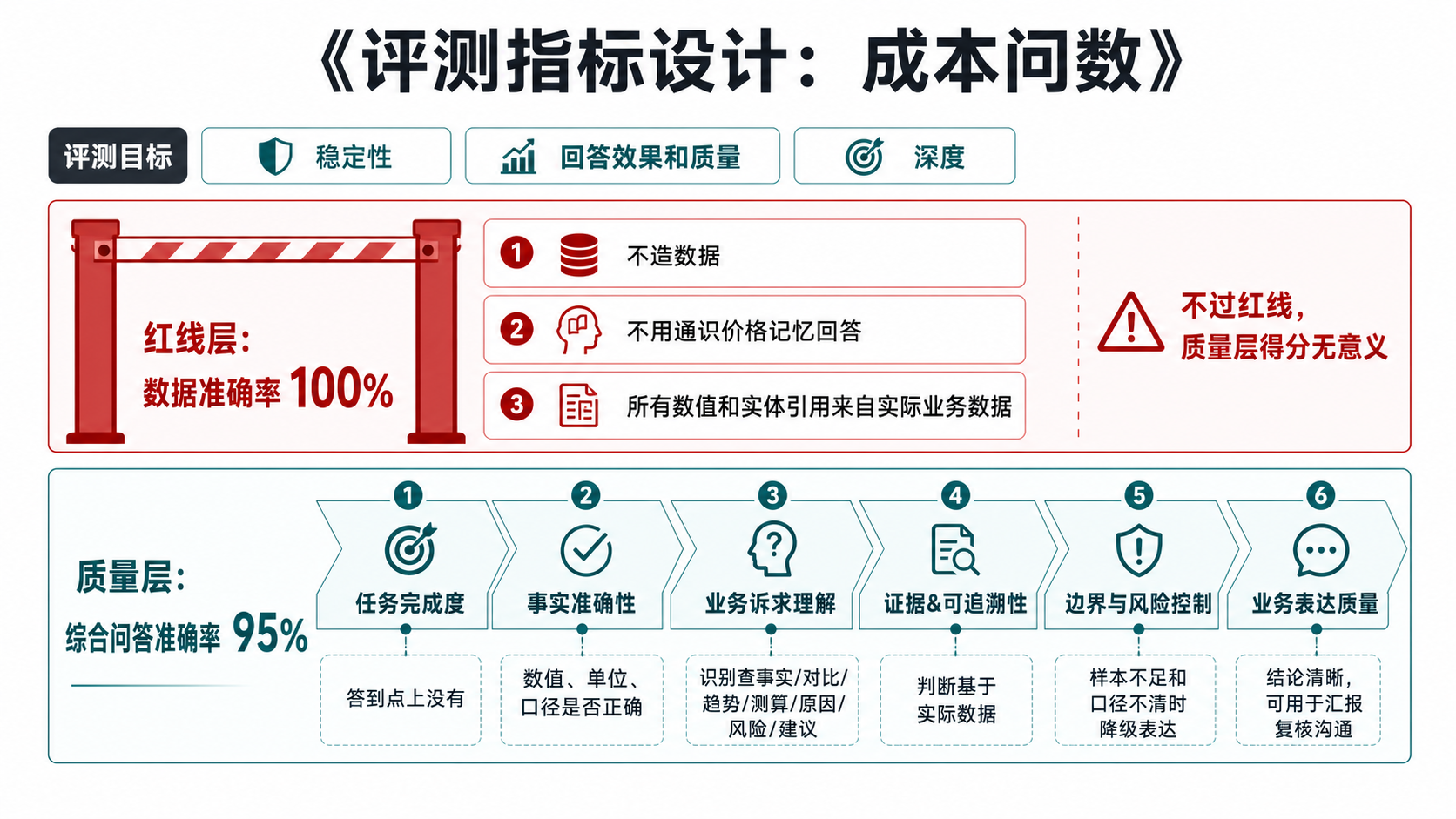
《评测指标设计:成本问数》
P56 · 评测数据集
评测集:决定出厂质量
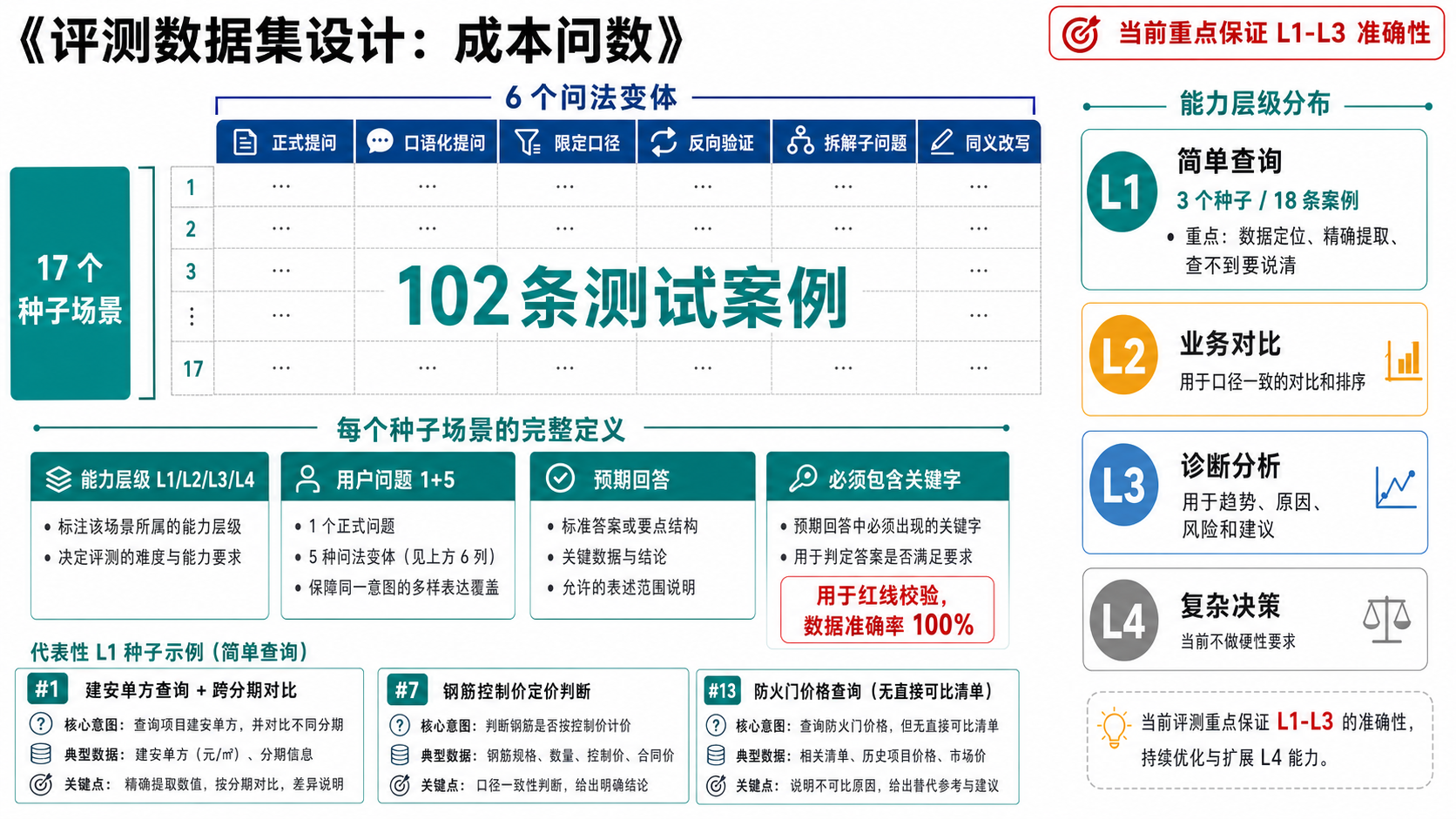
《评测数据集设计:成本问数》· 17 种子场景 / 102 案例 / L1–L4 分层
同一评测集 · 一把尺子量到底
95
我们的 Skill
vs
90
友商