CLI + 本体
CLI,是给 Agent 设计的指令系统
传统 CLI · 给人用
- · 服务对象:人类开发者
- · 设计目标:覆盖所有功能选项
- · 输出:给人读的文本日志、报错堆栈
- · 命令来自:API / 工具的能力清单
AI 原生 CLI · 给模型用
- · 服务对象:Agent(大模型)
- · 设计目标:完成一个业务动作
- · 输出:JSON + error_code + hint,机器可解析
- · 命令来自:业务任务,不是 API 路径
同一个问题,两种发起方式
脚本模式 · 面向「文件」
- · 含长路径 + 一堆参数,单次约 200 字符
- · 路径猜错、Windows 引号、编码错全在这行翻车
CLI 模式 · 面向「指令」
- · 统一命令
report-gen,单次约 100 字符 - · 命令在 PATH 里 —— 无路径、单入口
一个完整案例:控制价审核的 CLI 设计与优化结果
report-gen 命令report-gen 是统一命令、装在 PATH 里;每步业务动作 = 一个子命令,price 异步任务拆 create/poll/fetch。CLI 化,把模型的动作空间收窄了
| 脚本模式下的问题 | CLI 化后的改善 | 具体例子 |
|---|---|---|
| 猜脚本路径失败 | CLI 在 PATH 里,模型不需知道物理位置 | report-gen price create 直接能跑,不用先 ls 满地找脚本 |
| Windows 路径 / 引号出错 | CLI 接参数、内部处理路径 | 模型不再写 "C:\Users\...\" 这种被引号转义掉的路径 |
| 模型试图改 Skill 源码 | Skill 目录无脚本可改 —— 物理隔离 | 模型想改 _rewrite.py 兜底 —— 现在目录里根本没有 .py |
| JSON / GBK 编码混乱 | CLI 统一封装读写编码 | 不再出现 UnicodeDecodeError: 'gbk',模型不碰大 JSON |
| 字段名靠猜,KeyError | CLI 输出稳定 schema | 模型不再猜 dimension / 业态 这种字段名 |
好 CLI 不是 API wrapper,是 AI 的业务动作接口
feishu 是统一命令前缀,后面跟业务动词 —— 不是 POST /open-apis/docx/v1/... 这种 API 路径。为什么要做本体:模型会"飘"
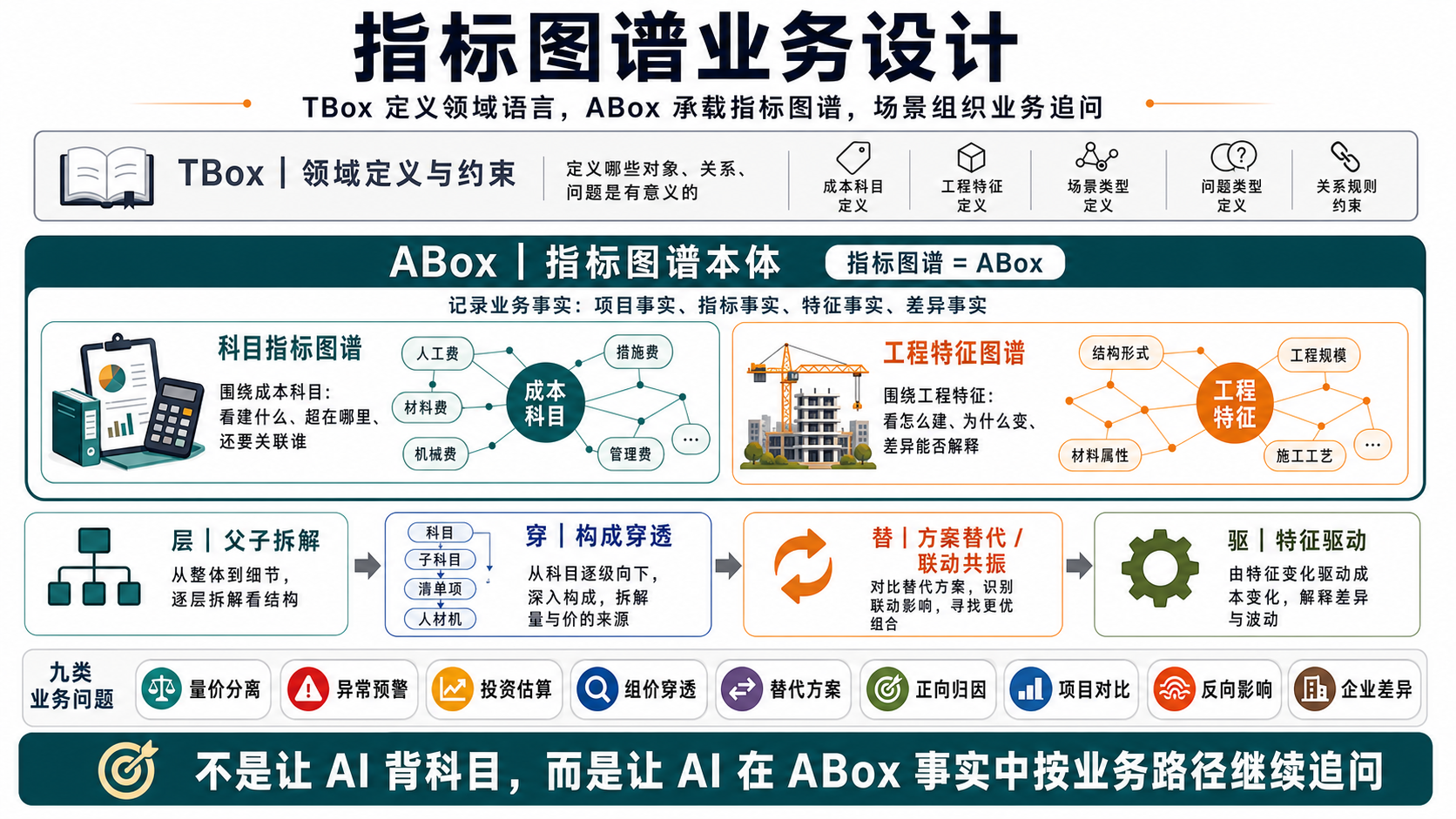
本体(Ontology)到底是什么
对一个领域内概念、类别及其关系的形式化表示 —— 给出一套共享词汇,对类型、属性、个体、关系建模。
组织的「数字孪生」 —— 把数据集映射到现实世界的对象、事件、流程,做成所有应用、AI 共用的语义层。
含税 / 不含税
结算状态
挂某成本科目
对应某供应商
算成本默认
用不含税
本体 = TBox + ABox
| TBox · 术语层 | ABox · 断言层 | |
|---|---|---|
| 是什么 | Schema / 数据模型 —— 定义有哪些类、属性、关系、约束规则 | Instance / 业务主数据 —— 描述真实数据的特征、数据之间的关联关系 |
| 回答的问题 | 「这个领域有哪些概念、它们结构上怎么定义」 | 「现实中具体有哪些东西、它们的值和关系是什么」 |
| 成本合同举例 | 成本合同 这个类,有「签约金额 / 含税 / 结算状态」等属性;规则:结算金额 = 签约金额 + 补差 | 「土建总承包合同 HT-2026-018」这份具体合同 —— 签约 2.4 亿、属于深圳湾一号项目、挂在土建科目下、对应 XX 建工 |
| 稳定性 | 更稳定 —— 像字典/数据模型,不常变 | 更动态 —— 像业务流水,随真实数据不断变 |
TBox 定义
「术语组件」—— 用一套类与属性,把领域词汇与结构定义出来。是定义性的,像一本字典。
ABox 定义
「断言组件」—— 在 TBox 模型之上,陈述具体事实:某个实例属于哪个类、有什么值、和谁有关系。
TBox 示例:成本问数的类型与约束
# TBox · 成本科目类型与约束 tbox: classes: - id: Class.ProjectIndicator label: 项目成本指标 dimensionProperties: - {name: costSubject, label: 成本科目} - {name: isEndCost, label: 是否末级科目} - {name: productType, label: 业态} measureProperties: - {name: jianAnAmount, label: 建安造价费} - {name: areaUnitCost, label: 建面单方} axioms: # 口径铁律 - rule: "默认只取末级科目 isEndCost=1" - rule: "父子科目不可混算(防重复)"
# ① 用户的业务问句 "深圳住宅的建安单方是多少?" # ② 转成查询 DSL(每个字段都来自 TBox) { cube: ProjectIndicator, # ← TBox 的类 measures: [areaUnitCost], # ← TBox 属性 filters: [ {productType: 住宅}, # ← TBox 维度 {city: 深圳} ] # isEndCost=1 由 axiom 自动补 }
讲个故事:如果没有 ABox,会发生什么
ABox 示例:一个下钻查询动作
# ABox · 真实业务事实 abox: instances: - {id: 土建工程, isEndCost: 0, amount: 2.4亿, areaUnitCost: 4250} - {id: 钢筋工程, parent: 土建工程, isEndCost: 1, contentRatio: 58kg/㎡} relations: # 共振:特征↑ 带动多个科目↑ - {type: resonance, driver: 结构层高, affects: [钢筋工程, 混凝土工程]} # 替代:两个方案二选一 - {type: substitute, options: [铝模方案, 木模方案]}
# Step 1 · 异常定位(L1/L2) 钢筋含量 58kg/㎡ > 同城样本 45 ⚠ # Step 2 · 沿 resonance 共振边下钻 钢筋工程 ←resonance← 结构层高 → 查得该项目层高 3.6m(样本 3.0m) # Step 3 · 沿 substitute 替代边比对 当前=木模方案,可选 铝模方案 → 铝模含量低 8%,但需评估成本 # 结论:层高刚性 + 模板可优化
ABox 长什么样:一张成本科目图谱
父子 · contains
土建工程 → 钢筋 / 混凝土 / 模板 —— 科目逐级拆解。
共振 · resonance
结构层高 → 同时带动钢筋、混凝土 —— 一个特征驱动多个科目。
替代 · substitute
铝模 ⇄ 木模 —— 互斥方案,归因时要拉出来比对。
什么时候只建 TBox,什么时候要上 ABox
只建 TBox 就够
- · L1 事实查询 —— 查一个项目、科目的值
- · L2 多维对比 —— 区域均值、项目排名、区间
- 有 Schema、有口径,就能查、能比
才需要上 ABox
- · L3 归因分析 —— 沿共振/替代关系下钻根因
- · L4 决策建议 —— 控价、谈判、降本建议
- 要顺着实例间的真实关系推理
| 查询类型 | 对接方式 | 典型场景 |
|---|---|---|
| 简单查询 | CLI 对接 API | 消息、待办 —— 取一条确定的数据,端点固定就够 |
| 复杂查询 | CLI 对接 宽表(+ 本体) | 资管台账、交易台账、合同 / 成本台账 —— 要多维组合、下钻归因 |
售楼问数 sales-query · 6 张宽表 + 18 题
| 宽表(物理表) | Cube 名(本体) | 行数 | 典型问数维度 |
|---|---|---|---|
| dwd_s_salesbudget · 销售目标 | SalesBudget | 221 | 项目 / 业态 / 年月 |
| dwd_s_room · 房间 | Room | 1,562 | 项目 / 楼栋 / 状态 / 户型 |
| dim_s_building · 楼栋 | Building | 46 | 项目 / 业态 |
| dwd_s_projectvalueabledetail · 楼栋货值 | ProjectValue | 207 | 项目 / 版本 / 层级 |
| dwd_s_order · 认购 | OrderDetail | 142 | 项目 / 类型 / 状态 / 顾问 |
| dwd_s_contract · 合同 | ContractDetail | 51 | 项目 / 类别 / 状态 / 顾问 |
L1 事实查询 · 8 题
"中建大公馆 2026 全年签约目标"、"各项目认购套数排名"。
L2 多维分析 · 7 题
"光谷天地每月认购金额趋势"、"按业态分组成交占比"。
L3 归因判断 · 3 题
"基准版项目全盘去化率"、"目标完成率风险研判"。
三层架构 · SKILL + CLI/DSL + 本体
统计成交"
拼 DSL JSON
编译 SQL
注入护栏 WHERE
① SKILL · 触发与编排
YAML description 写触发词、正文写调用流程。不连数据库、不写 SQL,只输出 DSL JSON 给 CLI。
② CLI / DSL 引擎
三个一级指令:find(行级)/aggregate(GROUP BY)/rank(Top-N)。接口窄、错不了。
③ 本体 schema.yaml
6 个 Cube 含 defaultFilters(护栏) + friendlyAlias(中文短名) + routed measure(单价路由)。
🔒 4 道口径护栏(自动注入,用户无感)
① OrderDetail/ContractDetail.Status=激活 — 排除关闭单,避免业绩翻倍
② OrderDetail.OrderType=认购 — 排除小订,避免混口径
③ ProjectValue.Level=3 AND IsBenchmark=1 — 避免三倍累加 + 多版本叠加 ★ 见下一页 P40 真实 bug
④ SalesBudget.Month<=12 — 排除全年汇总行(Month=13),避免翻倍
把这套复制走 · sales-query 资产
.claude/skills/sales-query/ ├── SKILL.md 98 行 ├── scripts/ │ ├── schema.yaml 326 行 · ★ 本体 │ ├── query.py 1,896 行 · DSL 引擎 │ └── cli.py 180 行 · SQL 执行 ├── references/ │ ├── dsl-spec.md DSL 关键字 + 自救 │ ├── query-guide.md 问数指南 │ └── schema/ # 6 个 Cube 各一份 │ ├── SalesBudget.md │ ├── Room.md / Building.md │ ├── ProjectValue.md │ ├── OrderDetail.md │ └── ContractDetail.md └── tests/ ├── questions.yaml 18 题 baseline └── run_e2e.py 端到端测试
SKILL.md(98 行) · 6 段
① YAML description 触发词 ② DSL 三指令导览 ③ 渐进披露:何时读 dsl-spec / schema md ④ Cube 速查表 ⑤ 7 类常见错+自救 ⑥ 不允许 JOIN 跨域
schema.yaml(326 行) · 每个 Cube 4 块
OrderDetail: table: dwd_s_order dimensions: [parentProjName, zygw, ...] measures: [cjTotal, cjBldArea, dealPrice] defaultFilters: # 口径护栏 - { field: status, value: 激活 } - { field: orderType, value: 认购 } friendlyAlias: # 中文短名 projectName: parentProjName
DSL 设计 · find / aggregate / rank 三指令
| DSL 指令 | 用途 | 关键字段 | 对应 SQL 语义 |
|---|---|---|---|
find | 行级查询 | cube · dimensions · filters · order · limit | SELECT ... WHERE ... LIMIT |
aggregate | 聚合分组 | cube · dimensions · measures · filters · having · having | SELECT ... GROUP BY ... HAVING |
rank | Top-N 排名 | cube · rankBy · dimensions · measures · limit | SELECT ... ORDER BY ... LIMIT N |
Q1 · 简单计数 · find
"中建大公馆 2026 全年签约目标"
sales-query find --dsl '{
"cube":"SalesBudget",
"filters":[
{"member":"projectName","operator":"contains","values":["中建大公馆"]},
{"member":"year","operator":"equals","values":[2026]},
{"member":"month","operator":"equals","values":[13]}
],
"dimensions":["budgetContractAmount"]
}'
→ 2600 万
Q2 · 分组排名 · aggregate
"各项目有效认购总金额"
sales-query aggregate --dsl '{
"cube":"OrderDetail",
"dimensions":["parentProjName"],
"measures":[{"member":"cjTotal","agg":"sum"}]
}'
→ 光谷天地 38,236,887 / 售楼考核 53,985,433…
自动加 WHERE Status=激活 AND OrderType=认购
Q3 · 时间分桶 · aggregate
"光谷天地每月认购金额趋势"
{
"cube":"OrderDetail",
"dimensions":[{
"member":"qsDate",
"granularity":"month"
}],
"measures":[{"member":"cjTotal","agg":"sum"}]
}
→ 1月 112万 / 2月 187万 / 3月 223万 / 4月 1326万
Q4 · 计算度量 · 去化率
"基准版项目全盘去化率"
measures:[
{"member":"soldValue","agg":"sum","alias":"已成交"},
{"member":"totalValue","agg":"sum","alias":"全盘"},
{"alias":"去化率",
"calc":"${已成交}/${全盘}"}
]
→ 光谷天地 10.0% / 中建大公馆 0%
自动加 WHERE level=3 AND isBenchmark=1
真实 bug 复盘:货值三倍累加 · 84 万 vs 28 万
❌ AI 直接写 SQL
SELECT SUM(TotalValue) FROM dwd_s_projectvalueabledetail WHERE IsBenchmark=1
- 结果:84,900,000 元 (8490 万)
- SQL 语法 100% 正确
- 但结果错 3 倍
✅ DSL 引擎自动加护栏
SELECT SUM(TotalValue) FROM dwd_s_projectvalueabledetail WHERE IsBenchmark=1 AND Level=3 -- 自动加
- 结果:28,300,000 元 (2830 万)
- 用户不传 level,本体自动补
- 口径正确
🔍 根因 · 宽表反范式的代价
dwd_s_projectvalueabledetail 同一份货值在 Level=1/2/3 三层各存一份等额金额(楼栋明细/分区明细/版本总计行)。
不锁 Level 直接 SUM → 同一笔货值被累加 3 次。
🛡️ 解法 · schema.yaml 写护栏
ProjectValue: defaultFilters: - field: level value: 3 unless: [level, hierarchyCode] hint: "默认 level=3
避免三倍累加"
P22 的两个问题 · DSL 当场答出来
✅ 问题 ① · 按置业顾问聚合
sales-query aggregate --dsl '{ "cube": "OrderDetail", "dimensions": ["zygw"], "measures": [ {"member":"rowCount","agg":"count"}, {"member":"cjTotal","agg":"sum"} ] }'
| 置业顾问 | 套数 | 成交总额 |
|---|---|---|
| 系统管理员 | 57 | 8,135 万 |
✅ 问题 ② · 项目成交总价汇总
sales-query aggregate --dsl '{ "cube": "OrderDetail", "filters": [ {"member":"projectName", "operator":"contains", "values":["光谷天地"]} ], "measures": [{"member":"cjTotal","agg":"sum"}] }'
| 项目 | 套数 | 成交总额 |
|---|---|---|
| 光谷天地 | 30 | 5,246 万 |
| 能力 | 实战 A · API 模式 | 实战 B · CLI + 本体 |
|---|---|---|
| 查明细台账(按项目/日期筛选) | ✅ 快、稳、口径固定 | ✅ |
| 按任意维度聚合(GROUP BY) | ❌ 没开端点就答不了 | ✅ aggregate 指令 |
| 排名 Top-N | ❌ | ✅ rank 指令 |
| 加一个新查询维度 | 改 API + 重启服务 | 换 DSL 参数,0 改代码 |
| 业务口径(如只算激活单) | 端点里写死 | 本体 defaultFilters 自动护栏 |